CSV File Formats
All data are loaded into a STEMgis database using ASCII comma separated value (CSV) files. Spatial and attribute data files are loaded separately into a STEMgis database. A spatial feature or object must exist in the database before any attributes can be loaded onto it, i.e. the spatial CSV file must be loaded before any related attribute CSV files are loaded. A number of sample files have been included with the STEMgis installation. These provide example of most different styles of CSV file that STEMgis uses. They are located in the data\samples sub-directory wherever STEMgis was installed. Please note that these sample files use the United Kingdom date format, i.e. day/month/year (e.g. 14/10/99). If you use a different date format, you may wish to temporarily change your Windows Regional Settings while loading these sample files.
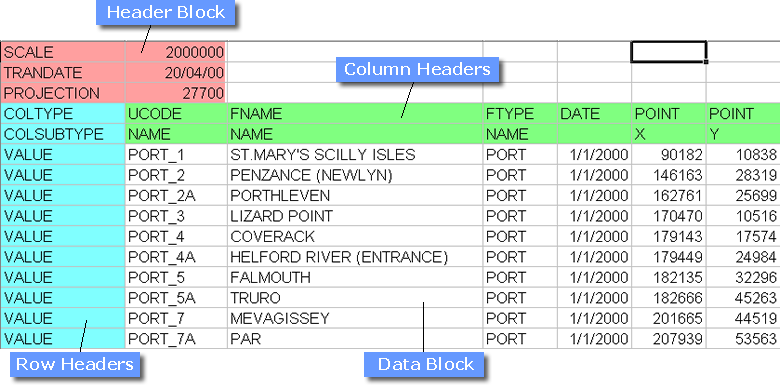
Spatial and attribute CSV files share a common form, i.e. each CSV file consists of a Header Block, a column of Row Headers, two rows of Column Headers and a Data Block containing one cell for each column header / VALUE combination. The final row header must contain the string EOF to terminate the file. This general structure is illustrated in the following table.
The table shows part of a spatial CSV file loaded into a spreadsheet - the actual ASCII file has commas within each row of text to define the positions of the columns. This spatial CSV file illustrates the format for a set of point features. The row following the final VALUE row must containthe string EOF only.
Note: The column separator, in this case a comma, is dependent on your regional settings on your PC. For example, German regional settings use a semi-colon (;) as the column separator. To check or change your regional settings go to the Control Panel and select Regional and Language Options. You will then see an entry for 'List Separator' which can be edited if you wish.
Note: When transferring data between PCs with different regional settings it is therefore advisable to use a binary format such as Microsoft Excel and then re-export the data as CSV format on the new PC. Microsoft Excel will use the appropriate regional setting as the column separator.
Spatial CSV files must contain the following:
| Structure | Compulsory Entry |
| Header Block | PROJECTION. |
| Row Headers | COLTYPE, COLSUBTYPE, VALUE, EOF - i.e. all four row headers are required. |
| Column Headers | UCODE, FNAME, FTYPE, DATE plus one of POINT, LINE, POLYGON, SURFACE, GRID or CORRECTION. |
| Data Block | A data value must be entered for each compulsory COLTYPE, i.e. UCODE, FNAME, FTYPE, DATE, and for each compulsory COLSUBTYPE of POINT, LINE, POLYGON, SURFACE, GRID or CORRECTION. The compulsory and optional elements of the various COLSUBTYPES are detailed in the tables below. For example, for the POINT COLTYPE the X and Y COLSUBTYPES are compulsory whereas the Z COLSUBTYPE is optional and may be entered in some cells and not in others as required. |
Attribute CSV files must contain the following:
| Structure | Compulsory Entry |
| Header Block | (No compulsory entries) |
| Row Headers | COLTYPE, COLSUBTYPE, VALUE, EOF - i.e. all four row headers are required. |
| Column Headers | UCODE, FTYPE, DATE plus at least one ATTRIB column. As many ATTRIB columns as required may be added. |
| Data Block | A data value must be entered for each compulsory COLTYPE, i.e. UCODE, FTYPE, DATE. (Entries under each ATTRIB COLTYPE are optional and may be entered in some cells and not in others, i.e. there does not have to be a data value for every cell in the data block.) |
Although the only mandatory header for a spatial file is the PROJECTION definition and there are no mandatory row headers for attribute files, the use of non-mandatory header information is encouraged as it often aids clarity.
Prior to loading, both spatial and attribute CSV files must be sorted by UCODE, DATE and/or TIME in that order, i.e. the definition of each feature must be ordered by date and time and not mixed out of chronological order and must not be interspersed with the definition of other features throughout a file. The Manager will warn you of any unsorted data in your file and you will be asked to re-order the data before reloading.
Most software packages will export CSV files of spatial or attribute data - these can be modified to add the necessary header information for STEMgis. A number of samples CSV files are located in the STEMgis installation directory under the sub-directory \samples.
A description of all Header Block, Row Header and Column Header keywords follows:
Header Block
Row Headers
Column Headers
The column headers depend on the input data. A description of the column headers in the example file is given here and a description of all possible column headers is given below.
| COLTYPE | COLSUBTYPE | Description |
| UCODE | NAME | Unique text string for a feature - this code must also be used when loading attributes onto a feature. This value is converted to an uppercase string before loading into the database, so do NOT differentiate between different features with upper/lower case characters. |
| FNAME | NAME | A full text name for the feature - this text is used as the full name of any feature in the Map Viewer |
| FTYPE | NAME | The four character code representing the feature type onto which the feature are to be loaded |
| DATE |
The date at which the feature occurs. The date can be a NULL date 01/01/100 which signifies that the feature is considered to be permanent through time. The format of the DATE and TIME columns should match the regional settings that are specified for your computer - you can check these using the Control Panel, selecting the 'Regional Settings' icon and then choosing the Date and Time tabs. Standard valid dates range from 01/01/100 through to 31/12/9999. However, STEMgis has a method of defining years outside of this range and can load any dates between 31,536,000,000 BC and 31,536,000,000 AD |
|
| POINT | X | The X co-ordinate of the point feature |
| POINT | Y | The Y co-ordinate of the point feature |
Three additional COLTYPEs could have been used for POINT features, these are:
| COLTYPE | COLSUBTYPE | Description |
| TEXTPOS | An integer value representing the position that the text is drawn relative to the point. This is used mainly for 'Place Name' feature types that have the TCODE set to 'PLAC'. | |
| TIME | The time at which the feature occurs - used in conjunction with data COLTYPE | |
| POINT | Z | The Z co-ordinate of the point feature |
Other spatial data is loaded in a similar way, simply change the COLTYPE headers, with each co-ordinate having a separate row but co-ordinates for the same feature instance having the same values for UCODE, FNAME and FTYPE:
| COLTYPE | COLSUBTYPE | Description | Required |
| LINE | X | The X co-ordinate of the line feature | Y |
| LINE | Y | The Y co-ordinate of the line feature | Y |
| LINE | Z | The Z co-ordinate of the line feature | N |
| POLYGON | X | The X co-ordinate of the polygon feature | Y |
| POLYGON | Y | The Y co-ordinate of the polygon feature | Y |
| POLYGON | Z | The Z co-ordinate of the polygon feature | N |
| SURFACE | X | The X co-ordinate of the surface feature | Y |
| SURFACE | Y | The Y co-ordinate of the surface feature | Y |
| SURFACE | Z | The Z co-ordinate of the surface feature | N |
One additional COLTYPE can be used for POLYGON features, e.g. the tigers1900polygons.csv sample file:
| COLTYPE | COLSUBTYPE | Description |
| ELEMENT | ID | This element ID value is used when loading polypolygon, i.e. a spatial feature which requires more than one polygon to define its extent, such as a country with lots of islands (i.e. lots of separate polygons defining the same entity) or a building with a courtyard in the middle (i.e. an outer polygon and an inner polygon defining the 'hole'). The ID value must start at 1 for the first polygon defining the polypolygon and should be incremented by one for each subsequent polygon belonging to the polypolygon feature. |
There are three further spatial data types, correction trapezia, grids and links. Their COLTYPEs are as follows:
| COLTYPE | COLSUBTYPE | Description | Required |
| CORRECTION | X | The X co-ordinate of the lower left of the grid feature | Y |
| CORRECTION | Y | The Y co-ordinate of the lower left of the grid feature | Y |
| CORRECTION | Z | The Z co-ordinate of the lower left of the grid feature | Y |
| CORRECTION | BEFORE_ATTRIB | The name of an attribute used to describe the state of elevation before correction | Y |
| CORRECTION | AFTER_ATTRIB | The name of an attribute used to describe the state of elevation after correction | Y |
| COLTYPE | COLSUBTYPE | Description | Required |
| GRID | X | The X co-ordinate of the lower left of the grid feature | Y |
| GRID | Y | The Y co-ordinate of the lower left of the grid feature | Y |
| GRID | Z | The Z co-ordinate of the lower left of the grid feature | N |
| GRID | NCOLS | The number of columns in the grid | Y |
| GRID | NROWS | The number of rows in the grid | Y |
| GRID | NLAYERS | The number of layers in the grid | N |
| GRID | CELLX | The X size of a grid cell | Y |
| GRID | CELLY | The Y size of a grid cell | Y |
| GRID | CELLZ | The Z size of a grid cell | N |
For larger images, retrieval performance can be improved by splitting the image into smaller tiles and loading each tile as a separate spatial entity. The recommended maximum tile size is 1500 x 1500 pixels, although you can load larger images if you wish.
Note: At present images can only be displayed in the projection with which they are loaded into the database. As a result, images may be turned off when you switch between different map projections.
| COLTYPE | COLSUBTYPE | Description | Required |
| LINK | FROMUCODE | The unique code of the spatial feature defining the beginning of the link | Y |
| LINK | TOUCODE | The unique code of the spatial feature defining the end of the link | Y |
LINK features are used to define virtual links between different spatial features and may be used to track attributes across these links. An example of this is points on a river network. If you wish to plot the attribute values as a transect down a river then link the individual points in the order with which they flow. You can then click on any point in the network to produce a transect of all the downstream links from the chosen point. The FROMUCODE and TOUCODE unique codes must already exist in the database.
Note: A link can be made between spatial features within different feature types.
Loading Attributes
Example files for loading attributes are provided in offsets.csv, urban_attribs.csv, swrivers_attribs.csv and tigerpop.csv. Multiple attribute columns may be defined in any input file with the following COLTYPE.
| COLTYPE | COLSUBTYPE | Description |
| ATTRIB | ACODE | ACODE refers to the attribute code defined in the definition of the attribute. The column contains the attribute values. |
Attributes are defined using the Manager tools and relate to one of the STEMgis data types. If you wish to load an 'ARRAY' data then the CSV file must include two ATTRIB columns, the first of which must refer to an attribute that has been defined as an ARRAY data type.
Loading Attributes with Depth
Example files for loading attributes with depth are provided in points_w_depth.csv, attribs_w_depth.csv. The spatial feature is defined as a 3D line and then attributes are loaded onto the vertices or elements of the line. The element needs to be identified within the CSV file as an additional column and may be defined in one of two ways:
| COLTYPE | COLSUBTYPE | Description |
| ELEMENT | ID | Identification of element within the array of vertices loaded on a 3D line. |
| ELEMENT | XYZ | When you are uncertain as to the order of the vertices then you can specify the XYZ co-ordinates and then original co-ordinates will be searched for an exact match before loading the attributes to each vertex. The format for XYZ is xstring:ystring:zstring e.g. 1234.56:2345.67:-12.3 |
Loading Image/Binary File/Movie Attributes
When loading images, binary files or movies as attributes the value in the ATTRIB column is a filename for the image, binary file or movie, see model_attrib.csv. If images are georeferenced then their associated spatial feature types will be grids. If the images are non-georeferenced then the associated feature types will be something other than grids, e.g. POINTs, LINEs or POLYGONs.
Note: Movie and binary file attributes can only be associated with point, line and polygon spatial features.
Note: The image attribute definitions must be set to GRIDC or GRIDR, the binary file attribute definitions to BINARY and the movie attribute definitions to MOVIE.
Other CSV File Formats
There are several additional CSV file formats that are used within STEMgis. These include:
Loading Image or Character Attribute Keys
User defined keys may be loaded for byte images (i.e. GRIDC attributes) or attributes defined as characters (i.e. CHAR attributes). To load key colour information use the following COLTYPEs and see an example file in modelkey.csv.
| COLTYPE | COLSUBTYPE | Description |
| FTYPE | NAME | The name of the feature type containing the data for which the key exists. |
| KEY | ATTRIB | The acode (attribute code) to which the key refers - this code is defined when the attribute is first set up and is also used when loaded attributes into the database. |
| KEY | NAME | The text that appears alongside the key colour |
| KEY | RED | The red component of the key colour - an integer 0-255 |
| KEY | GREEN | The green component of the key colour - an integer 0-255 |
| KEY | BLUE | The blue component of the key colour - an integer 0-255 |
For continuous keys only five of the key names will be shown, but it is recommended that you load all of the names in the sequence. If there are more than 30 entries in a key information file relating to an image attribute then they are considered to represent a continuous colour range as in the right-hand example above.
Loading Period Data
Spatial data can change its definition through time by simply loading spatial data with different times for the same UCODE. However, it is sometimes necessary to have spatial features that have a consistent spatial definition through time but that be irrelevant or 'turned off' at certain times. An example of this might be an archaeological site that is only relevant during certain periods of history or a railway line that becomes disused for a while before then being reopened.
To use this functionality within STEMgis you should load a CSV file with UCODE, FTYPE, DATE and PERIOD (see table below) COLTYPEs. There are 3 sample files in the samples directory - TESTONOFF*.csv, which show how to use the PERIOD COLTYPE.
| COLTYPE | COLSUBTYPE | Description |
| PERIOD | ONOFF | A text string that is either "ON" or "OFF" indicating |
Loading Regular/Irregular Time Series Data
If you have a large amount of attribute data associated with one spatial feature it can be quite expensive, in terms of database size and retrieval times, to store each value in a separate row in the STEMgis database. TIMEINT and TIMESER COLTYPEs can be used to define regular and irregular time series data which are stored as binary arrays in the database. The associated attributes are also stored as compressed binary arrays which saves on space and retrieval times by a factor of more than 100.
To load regular time series data, which might include model type data or regularly measured sites, use the TIMEINT COLTYPE.
| COLTYPE | COLSUBTYPE | Description | Required |
| TIMEINT | TLABEL | A unique label given to the time series, equivalent to the UCODE for a spatial feature | Y |
| TIMEINT | STARTDATE | The start date of the time series | Y |
| TIMEINT | STARTTIME | The start time of the time series | N |
| TIMEINT | NTIMES | The number of times within the time series | Y |
| TIMEINT | INCSEC | The number of seconds within the regular time interval | N (one of the remaining columns is required) |
| TIMEINT | INCMIN | The number of minutes within the regular time interval | N |
| TIMEINT | INCHOUR | The number of hours within the regular time interval | N |
| TIMEINT | INCDAY | The number of days within the regular time interval | N |
| TIMEINT | INCMONTH | The number of months within the regular time interval | N |
| TIMEINT | INCYEAR | The number of years within the regular time interval | N |
Note: At least one of the increment columns is required to define the time increment used within the time series. If more than one increment column is used then each increment value is summed to calculate the interval period.
Note: Any number of TLABELs may be defined in one CSV file.
To load irregular time series data, use the TIMESER COLTYPE.
| COLTYPE | COLSUBTYPE | Description | Required |
| TIMESER | TLABEL | A unique label given to the time series, equivalent to the UCODE for a spatial feature | Y |
| TIMESER | TSDATE | An individual date within the time series | Y |
| TIMESER | TSTIME | An individual date within the time series | N |
Note: The individual date/time elements must be in chronological order. You can only have one TLABEL per CSV file.
Once you have loaded a time series definition you can then load related attribute data. This is done using a standard attribute CSV file but by replacing the date and/or time COLTYPEs with ALTDATE COLTYPEs which address a position within a time series (see below).
| COLTYPE | COLSUBTYPE | Description | Required |
| ALTDATE | TLABEL | A unique label given to the time series, equivalent to the UCODE for a spatial feature | Y |
| ALTDATE | TPOS | A position within the time series array to which the attribute refers | Y |
Note: TPOS starts at 1 not zero.
Examples of the time series and related attribute files are given in the samples directory - TIMESER*.csv and TIMEINT*.csv.
Loading Array Type Data
All attribute data described so far has been loaded relative to date/time and 3D space. You may have data which is inextricably linked to another attribute at any instant in time. Such data might include an attribute versus cumulative percentage or reflectance versus wavelength. This type of data is best loaded as an ARRAY. All ARRAY data is loaded as pairs of attribute values linked by an ARRAY ID number. The additional COLTYPEs that are required are listed below.
| COLTYPE | COLSUBTYPE | Description | Required |
| ARRAY | ID | The array element of the pair of attribute values | Y |
| ATTRIB | ACODE | ACODE refers to the attribute code defined in the definition of the attribute for the dependent attribute (e.g. cumulative % in the example above). The column contains the attribute values. | Y |
| ATTRIB | ACODE | ACODE refers to the attribute code defined in the definition of the attribute for the second attribute. The column contains the attribute values. Only two ATTRIB columns are allowed. | Y |
An example of ARRAY data is given in samples directory - TestArray.csv
Attribute definitions can be added individually using the user interface method provided under the Tools menu. However, to load many definitions simultaneously the ATTDEF CSV file format can be used. The column definitions are described below.
| COLTYPE | COLSUBTYPE | Description | Required |
| ATTDEF | NAME | The full name of the attribute which appears in the Query Wizard, Map Key etc. | Y |
| ATTDEF | ATTRIB | The attribute code that is stored in the database. It is also the code that is used in ATTRIB and ARRAY CSV files. | Y |
| ATTDEF | DICT | The Dictionary code of the dictionary with which the attribute should be associated, e.g. CHEM for the Chemical Dictionary | Y |
| ATTDEF | UNIT | The Unit code of the attribute unit. Check in the Units definitions under the Manage Features, Attributes etc menu item of the Tools menu. | Y |
| ATTDEF | SCODE | The structure code of the attribute, e.g. REAL for single precision real number. Click here for full options. | Y |
| ATTDEF | RED | A value between 0 and 255 representing the red component of the colour assigned to the attribute. | N |
| ATTDEF | GREEN | A value between 0 and 255 representing the green component of the colour assigned to the attribute. | N |
| ATTDEF | BLUE | A value between 0 and 255 representing the blue component of the colour assigned to the attribute. | N |
An example of ATTDEF data is given in samples directory - attdef.csv
Note: Apart from ARRAYs the various groups of COLTYPE headers may not appear in the same file. You must load spatial, attribute, key, period and time series information separately.
Note: Every file MUST end in 'EOF' on a line by itself.
Using the sample files
The sample files are included in the data\samples sub-directory, wherever STEMgis has been installed.
Before loading the sample files, you should define the Feature Types and Attributes defined in each of the files. The following table shows the codes that are used:
| Feature Type | Feature Type Name | TCODE | Attribute Code | Attribute Name | Data Type |
| PORT | Port Offsets | CDLD | Chart to local datum | Real | |
| URBN | Urban Areas | CDOD | Chart to Ordnance datum | Real | |
| ERSM | ERSEM Model | ALKA | Alkalinity | Real | |
| BLAH | Test point data | IRON | Iron dissolved | Real | |
| PTTI | Test points with time | ECHLOR | Chlorophyll modelled | Gridc | |
| ROAD | Traffic Survey | EAMM | Ammonium modelled | Gridc | |
| SWRV | Rivers | EBACT | Bacteria modelled | Gridc | |
| TIGD | Tiger distribution | BorePhoto | Borehole photograph | Gridc | |
| POR2 | Port Place Names | PLAC | CSPEED | Current speed | Real |
| OOTE | Period On/Off Test | CDIR | Current direction | Real | |
| DBTS | Time interval test | ROADSPEED | Average road speed | Real | |
| ROSF | Irregular time series test | TRAFFICVOL | Traffic Volume | Real | |
| ATTC | Test Character Attribute | Char | |||
| ATTR | Test Real Attribute | Real | |||
| ATTI | Test Integer Attribute | Integer | |||
| TIGERPOP | Tiger Population | Real | |||
| CUMUL | Cumulative | Real | |||
| HUMANPOP | Human Population | Real |
| Browser Based Help. Published by chm2web software. |